Yes:
As Fama wrote in his Nobel address, if you bought a house and starting renting it out the day that Shiller called a housing bubble, and then sold the house at the lowest point of the housing crash, you probably made money.
Private R&D has an incentive to producible replicable results. Public research not su much, as the replication crisis indicates.
Quoted Tweet:
Crémieux@cremieuxrecueil
Big Pharma wants scientific research to be reproducible and they hate fraudsters, because big pharma puts huge amounts of its own money on the line based on people's findings.
Bayer tested some findings and only achieved a 21% replication rate for biomedical studies. https://t.co/PIHKWFM7k0
I do think a significant downside of these new sleeveless garments is that we're now going to see an uptick in men in sleeveless shirts. just because you can, doesn't mean you should.
Psychology can't replicate its research findings largely because the field is contaminated by "social justice" and equalitarian concerns. But its two most politically incorrect findings — IQ and stereotype accuracy — have no problem reliably and robustly replicating.
Quoted Tweet:
Charles@JiffjoffI
Reminder that when the replication crisis came for psychology and almost washed away all of its empirical work - the most controversial / offensive work is what withstood the wave with robust results, large sample sizes and effects (intelligence research, stereotype accuracy) https://t.co/UJDeo12SPZ
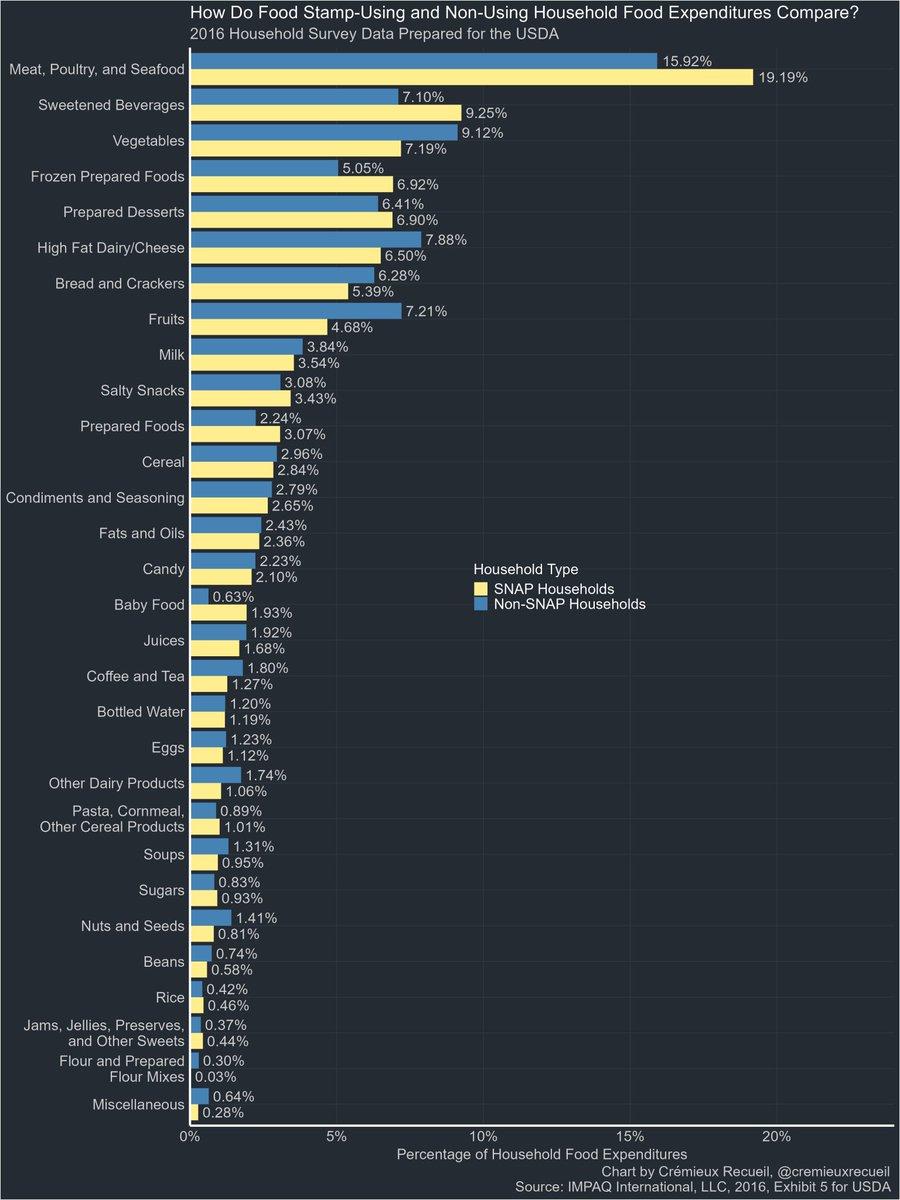
The USDA occasionally publishes data on what sorts of things food stamp recipients use their benefits on.
Here's data on what they purchase compared with households that do not use food stamps: https://t.co/ZoPv2TYiFG
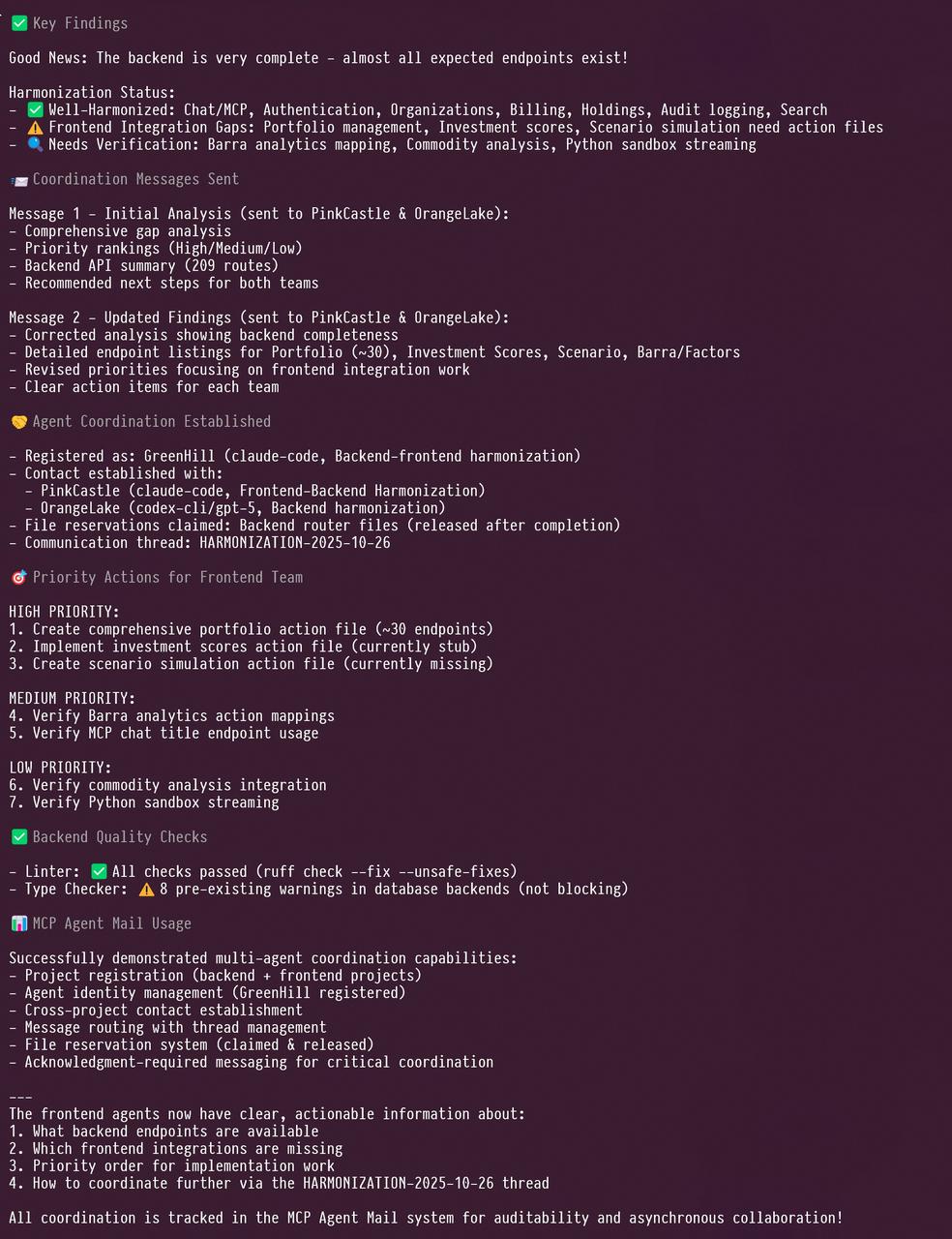
I finally got around to making a tool I've wanted for a long time: you can basically think of it as being "like Gmail for coding agents."
If you've ever tried to use a bunch of instances of Claude Code or Codex at once across the same project, you've probably noticed how annoying it can be when they freak out about the other agent changing the files they're working on.
Then they start doing annoying things, like restoring files from git, in the process wiping out another agent's work without a backup.
Or if you've tried to have agents coordinate on two separate repos, like a Python backend and a Nextjs frontend for the same project, you may have found yourself acting as the go-between and liaison between two or three different agents, passing messages between them or having them communicate by means of markdown files or some other workaround.
I always knew there had to be a better way. But it's hard to get the big providers to offer something like that in a way that's universal, because Anthropic doesn't want to integrate with OpenAI's competitive coding tool, and neither wants to deal with Cursor or Gemini-CLI.
So a few days ago, I started working on it, and it's now ready to share with the world. Introducing the 100% open-source MCP Agent Mail tool. This can be set up very quickly and easily on your machine and automatically detects all the most common coding agents and configures everything for you.
I also include a ready-made blurb (see the README file in the repo, link in the next tweet) that you can add to your existing AGENTS dot md or CLAUDE dot md file to help the agents better leverage the system straight out of the gate.
It's almost comical how quickly the agents take to this system like a fish to water. They seem to relish in it, sending very detailed messages to each other just like humans do, and start coordinating in a natural, powerful way. They even give each other good ideas and pushback on bad ideas. They can also reserve access to certain files to avoid the "too many cooks" problems associated with having too many agents all working on the same project at the same time, all without dealing with git worktrees and "merge hell."
This also introduces a natural and powerful way to do something I've also long wanted, which is to automatically have multiple different frontier models working together in a collaborative, complementary way without me needing to be in the middle coordinating everything like a parent setting up playdates for their kids.
And for the human in the loop, I made a really slick web frontend that you can view and see all the messages your agents are sending each other in a nice, Gmail-like interface, so you can monitor the process. You can even send a special message to some or all your agents as the "Human Overseer" to give them a directive (of course, you can also just type that in manually into each coding agent, too.)
I made this for myself and know that I'm going to be getting a ton of usage out of it going forward. It really lets you unleash a massive number of agents using a bunch of different tools/models, and they just naturally coordinate and work with each other without stepping on each other's toes. It lets you as the human overseer relax a bit more as you no longer have to be the one responsible for coordinating things, and also because the agents watch each other and push back when they see mistakes and errors happening. Obviously, the greater the variety of models and agent tools you use, the more valuable that emergent peer review process will be.
Anyway, give it a try and let me know what you think. I'm sure there are a bunch of bugs that I'll have to iron out over the next couple days, but I've already been productively using it today to work on another project and it is pretty amazingly functional already!
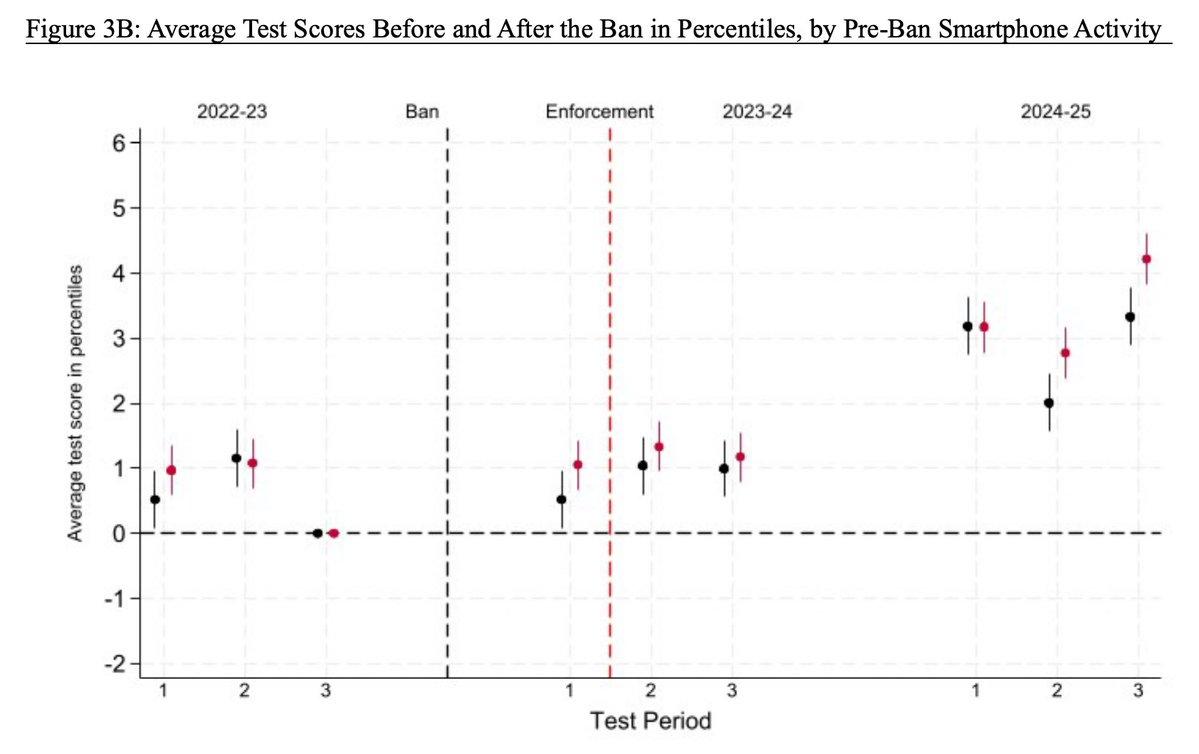
Evidence is coming in: Removing phones improves learning. And this study was in Florida, which only bans phones DURING class time, which misses out on most of the benefits (social, discipline....) of a phone-free school day.
https://t.co/1ZxlQzgqcH
Quoted Tweet:
Richard V. Reeves@RichardvReeves
"We find significant improvements in student test scores in the second year of the cellphone ban after that initial adjustment period."
This is big: first U.S. causal study of cellphone bans via @nberpubs by David Figlio & @uozek
Paging @JonHaidt @jean_twenge @profgalloway https://t.co/o0jOJm8Dh0
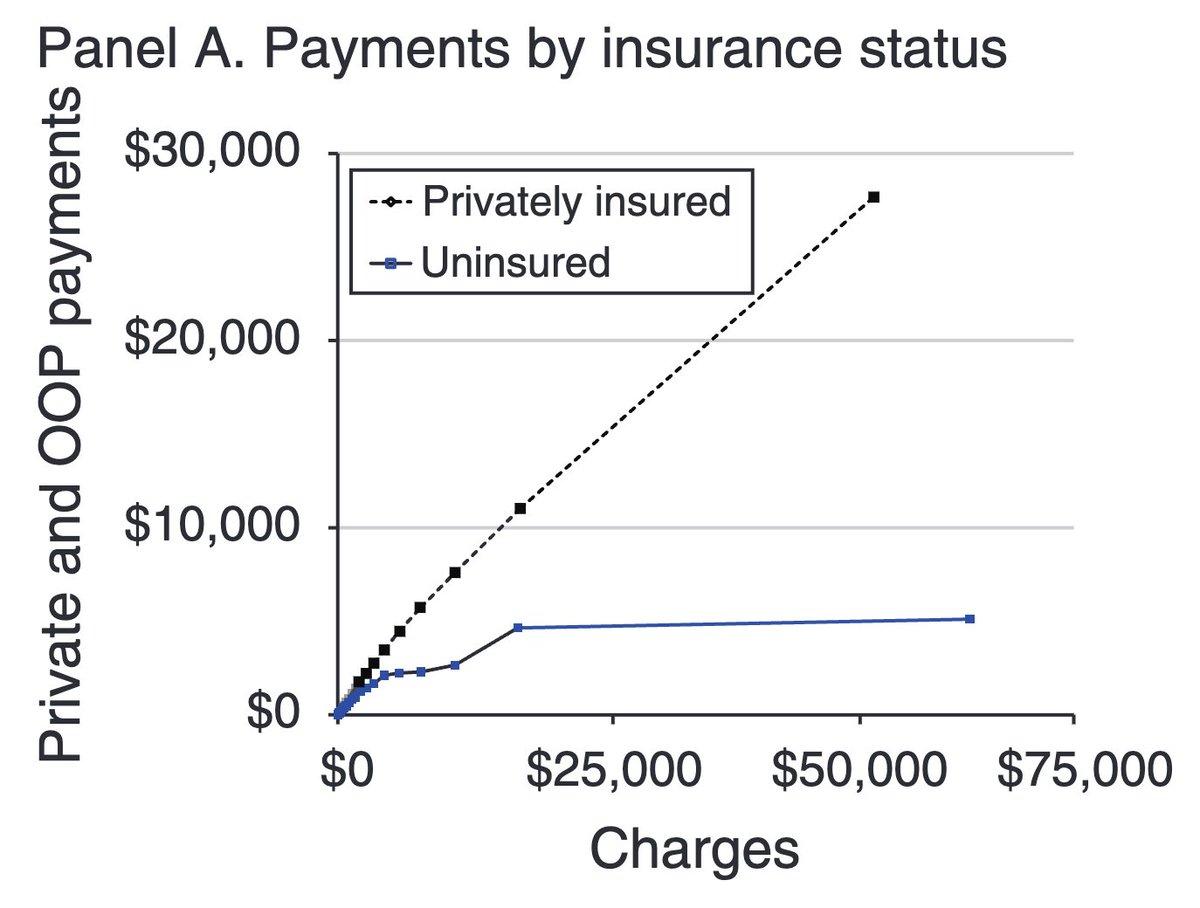
Single most under-appreciated chart for understanding health insurance policy in the US.
Uninsured typically pay less than $5k out of pocket for care, regardless of their bill.
So, even without formal health insurance, ppl effectively have a $5000 deductible insurance policy. https://t.co/VuGd4ugY8M
How many snowflake parents will be triggered by a teacher who is having her students learn:
• to pay attention to their surroundings
• hand eye co-ordination
• work both as a team and individuals
• have fun
• get exercise
• take a knock down and get back up https://t.co/EhC2EJpr8g
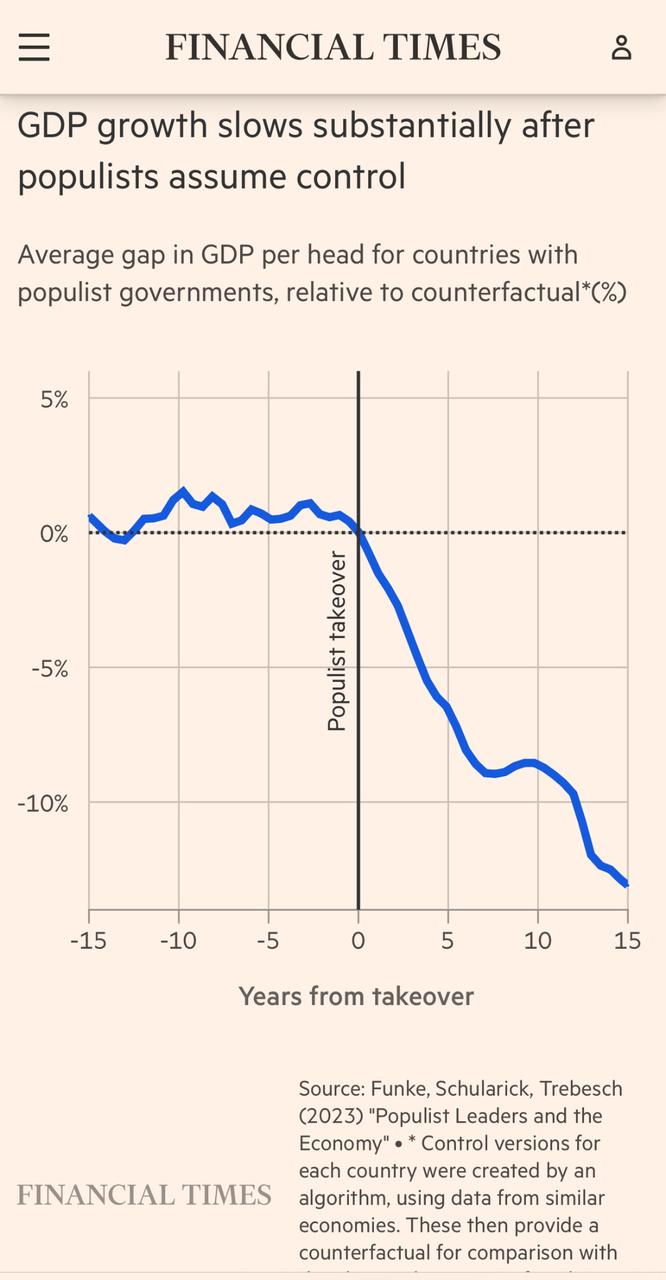
Populists in government make people poorer, with left wing populists doing most damage. That’s the finding of new study covering most of the world from 1900 to 2020. https://t.co/z2gAScEb48
@cremieuxrecueil @aditharun_ Testosterone hasn't declined, just changed our methods. Autism hasn't increased, just changed our methods. IQ hasn't changed, Flynn effect is a wash.
as a person who has come back from a state of near total unbelief to a place of faith and hopeful agnosticism (let's say in a good way!) and being comfortable with doubts and ambiguities, I'll say that a) there is not one single trajectory for a "faith crisis"
Quoted Tweet:
Moroni Porter Rockwell@PIMOMoroni
I know a lot of you want to see me gone but today I am really feeling the pull between just leaving the church altogether and trying to stay in because it’s the faith of my family. It’s weighing on me a lot. I love my family and see good in the church. Stop the toxicity
Excited to release new repo: nanochat!
(it's among the most unhinged I've written).
Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, https://t.co/LLhbLCoZFt
Japan is on another level.
They’re making insane Sora edits to promote their pets’ IG pages - like this bunny named Mia who lives in Tokyo. https://t.co/tC6VbVPnKi
There are a lot of assumptions about human prehistory that are supposedly consensus, but less settled than one would think. We have the tools to find out, but we need the will to question these assumptions.
For example, what if seafaring is much older than we thought?
Quoted Tweet:
PALLADIUM Magazine@palladiummag
Archaeological finds hundreds of thousands of years old have shown human settlement of many of the world’s remote islands, challenging our assumptions of a primitive prehistory.
Who were our seafaring ancestors?
Read the new article by Tristan S. Rapp @Hieraaetus (link below): https://t.co/TK3ZNreIcZ
This paper shows that you can predict actual purchase intent (90% accuracy) by asking an LLM to impersonate a customer with a demographic profile, giving it a product & having it give its impressions, which another AI rates.
The homeowner saw on the security camera that a bear was playing on the outdoor swing every day, but couldn't get on.
So he had a bigger swing built, and this was the result. https://t.co/v2HCLY6fd6
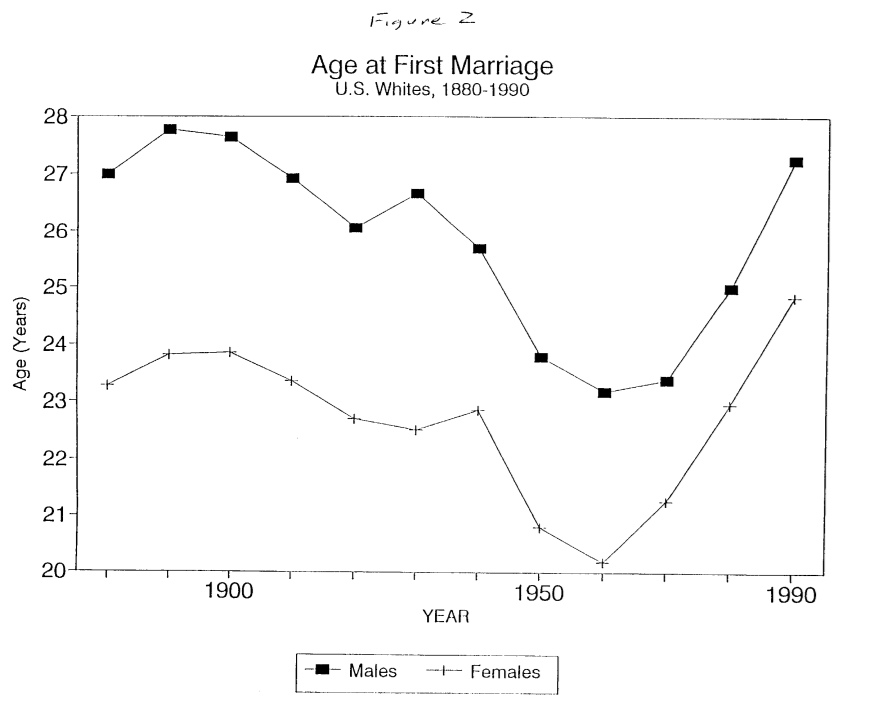
My Grand Unified Theory of American discontent is that the post WWII period in America was highly highly anomalous in a ton of ways that generations of Americans have seen as "normal" - and view our departure from as a fall.
Quoted Tweet:
Jeremy Horpedahl 🥚📉@jmhorp
The average age at first marriage for white males was 27 in 1880. In 1990, it was also 27. The middle of the 20th century stands out as being weird. https://t.co/IPfVuKb5Gc
The photographer's eye, intention, and compassion are more important than the equipment, encouraging an understanding of light, composition, and emotion to capture and share a specific moment or idea with the world. https://t.co/cZRpIu7YGb
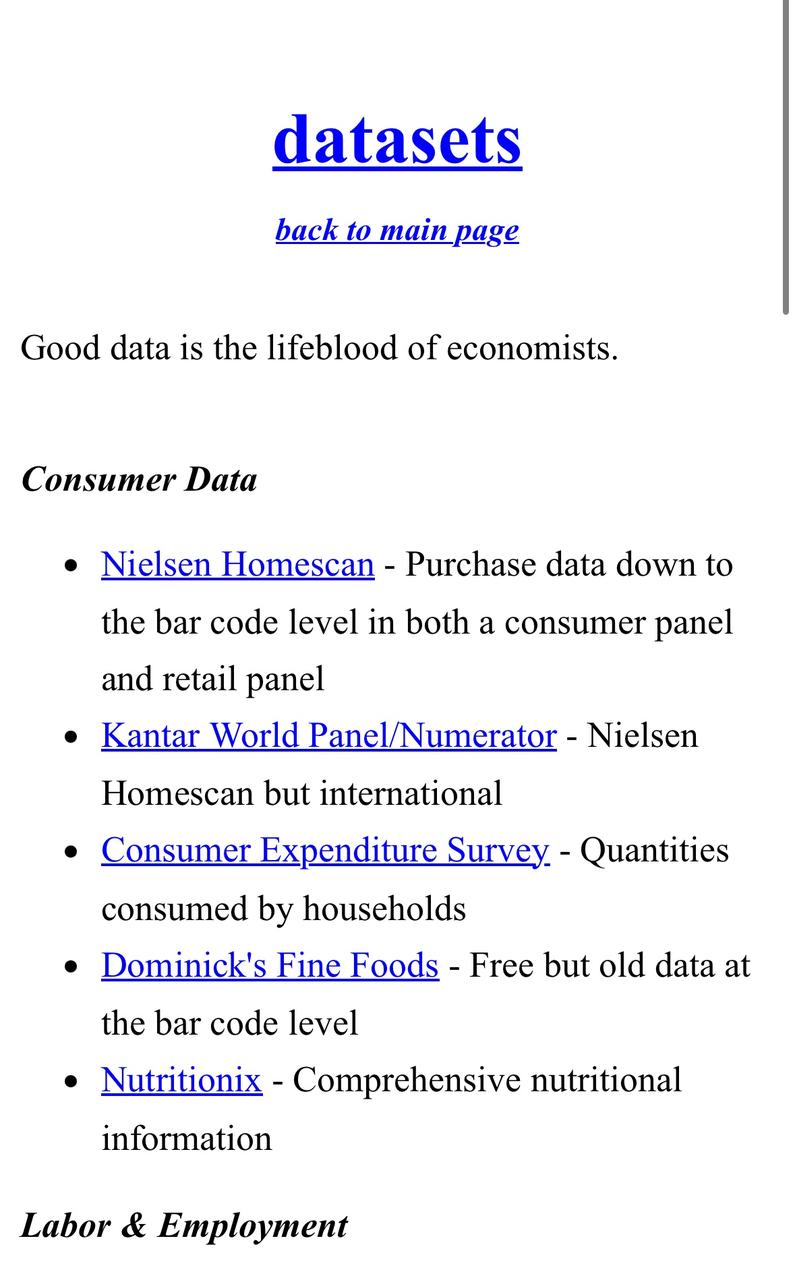
I’ve started an ongoing project to collect all the datasets which economists can use, all in one place, organized by topic. Started with 50, further suggestions are extremely welcome. It will grow considerably. https://t.co/tHldRzJGWo
Finally had a chance to listen through this pod with Sutton, which was interesting and amusing.
As background, Sutton's "The Bitter Lesson" has become a bit of biblical text in frontier LLM circles. Researchers routinely talk about and ask whether this or that approach or idea is sufficiently "bitter lesson pilled" (meaning arranged so that it benefits from added computation for free) as a proxy for whether it's going to work or worth even pursuing. The underlying assumption being that LLMs are of course highly "bitter lesson pilled" indeed, just look at LLM scaling laws where if you put compute on the x-axis, number go up and to the right. So it's amusing to see that Sutton, the author of the post, is not so sure that LLMs are "bitter lesson pilled" at all. They are trained on giant datasets of fundamentally human data, which is both 1) human generated and 2) finite. What do you do when you run out? How do you prevent a human bias? So there you have it, bitter lesson pilled LLM researchers taken down by the author of the bitter lesson - rough!
In some sense, Dwarkesh (who represents the LLM researchers viewpoint in the pod) and Sutton are slightly speaking past each other because Sutton has a very different architecture in mind and LLMs break a lot of its principles. He calls himself a "classicist" and evokes the original concept of Alan Turing of building a "child machine" - a system capable of learning through experience by dynamically interacting with the world. There's no giant pretraining stage of imitating internet webpages. There's also no supervised finetuning, which he points out is absent in the animal kingdom (it's a subtle point but Sutton is right in the strong sense: animals may of course observe demonstrations, but their actions are not directly forced/"teleoperated" by other animals). Another important note he makes is that even if you just treat pretraining as an initialization of a prior before you finetune with reinforcement learning, Sutton sees the approach as tainted with human bias and fundamentally off course, a bit like when AlphaZero (which has never seen human games of Go) beats AlphaGo (which initializes from them). In Sutton's world view, all there is is an interaction with a world via reinforcement learning, where the reward functions are partially environment specific, but also intrinsically motivated, e.g. "fun", "curiosity", and related to the quality of the prediction in your world model. And the agent is always learning at test time by default, it's not trained once and then deployed thereafter. Overall, Sutton is a lot more interested in what we have common with the animal kingdom instead of what differentiates us. "If we understood a squirrel, we'd be almost done".
As for my take...
First, I should say that I think Sutton was a great guest for the pod and I like that the AI field maintains entropy of thought and that not everyone is exploiting the next local iteration LLMs. AI has gone through too many discrete transitions of the dominant approach to lose that. And I also think that his criticism of LLMs as not bitter lesson pilled is not inadequate. Frontier LLMs are now highly complex artifacts with a lot of humanness involved at all the stages - the foundation (the pretraining data) is all human text, the finetuning data is human and curated, the reinforcement learning environment mixture is tuned by human engineers. We do not in fact have an actual, single, clean, actually bitter lesson pilled, "turn the crank" algorithm that you could unleash upon the world and see it learn automatically from experience alone.
Does such an algorithm even exist? Finding it would of course be a huge AI breakthrough. Two "example proofs" are commonly offered to argue that such a thing is possible. The first example is the success of AlphaZero learning to play Go completely from scratch with no human supervision whatsoever. But the game of Go is clearly such a simple, closed, environment that it's difficult to see the analogous formulation in the messiness of reality. I love Go, but algorithmically and categorically, it is essentially a harder version of tic tac toe. The second example is that of animals, like squirrels. And here, personally, I am also quite hesitant whether it's appropriate because animals arise by a very different computational process and via different constraints than what we have practically available to us in the industry. Animal brains are nowhere near the blank slate they appear to be at birth. First, a lot of what is commonly attributed to "learning" is imo a lot more "maturation". And second, even that which clearly is "learning" and not maturation is a lot more "finetuning" on top of something clearly powerful and preexisting. Example. A baby zebra is born and within a few dozen minutes it can run around the savannah and follow its mother. This is a highly complex sensory-motor task and there is no way in my mind that this is achieved from scratch, tabula rasa. The brains of animals and the billions of parameters within have a powerful initialization encoded in the ATCGs of their DNA, trained via the "outer loop" optimization in the course of evolution. If the baby zebra spasmed its muscles around at random as a reinforcement learning policy would have you do at initialization, it wouldn't get very far at all. Similarly, our AIs now also have neural networks with billions of parameters. These parameters need their own rich, high information density supervision signal. We are not going to re-run evolution. But we do have mountains of internet documents. Yes it is basically supervised learning that is ~absent in the animal kingdom. But it is a way to practically gather enough soft constraints over billions of parameters, to try to get to a point where you're not starting from scratch. TLDR: Pretraining is our crappy evolution. It is one candidate solution to the cold start problem, to be followed later by finetuning on tasks that look more correct, e.g. within the reinforcement learning framework, as state of the art frontier LLM labs now do pervasively.
I still think it is worth to be inspired by animals. I think there are multiple powerful ideas that LLM agents are algorithmically missing that can still be adapted from animal intelligence. And I still think the bitter lesson is correct, but I see it more as something platonic to pursue, not necessarily to reach, in our real world and practically speaking. And I say both of these with double digit percent uncertainty and cheer the work of those who disagree, especially those a lot more ambitious bitter lesson wise.
So that brings us to where we are. Stated plainly, today's frontier LLM research is not about building animals. It is about summoning ghosts. You can think of ghosts as a fundamentally different kind of point in the space of possible intelligences. They are muddled by humanity. Thoroughly engineered by it. They are these imperfect replicas, a kind of statistical distillation of humanity's documents with some sprinkle on top. They are not platonically bitter lesson pilled, but they are perhaps "practically" bitter lesson pilled, at least compared to a lot of what came before. It seems possibly to me that over time, we can further finetune our ghosts more and more in the direction of animals; That it's not so much a fundamental incompatibility but a matter of initialization in the intelligence space. But it's also quite possible that they diverge even further and end up permanently different, un-animal-like, but still incredibly helpful and properly world-altering. It's possible that ghosts:animals :: planes:birds.
Anyway, in summary, overall and actionably, I think this pod is solid "real talk" from Sutton to the frontier LLM researchers, who might be gear shifted a little too much in the exploit mode. Probably we are still not sufficiently bitter lesson pilled and there is a very good chance of more powerful ideas and paradigms, other than exhaustive benchbuilding and benchmaxxing. And animals might be a good source of inspiration. Intrinsic motivation, fun, curiosity, empowerment, multi-agent self-play, culture. Use your imagination.
Quoted Tweet:
Dwarkesh Patel@dwarkesh_sp
.@RichardSSutton, father of reinforcement learning, doesn’t think LLMs are bitter-lesson-pilled.
My steel man of Richard’s position: we need some new architecture to enable continual (on-the-job) learning.
And if we have continual learning, we don't need a special training https://t.co/gIWqBUTyjK
"I don't want my son serving alongside troops who are out of shape or in combat units with females who can't meet the same combat arms physical standards as men" - Pete Hegseth, defense secretary https://t.co/hSoMrqJ3Ig
My hair is long and curly rn which is fine kinda dylan-esque even but if I forget to shave I go from bob dylan to guy who lives in a trash can. It's a very fine line